A Practical Framework for Identifying Opportunities in Artificial Intelligence
Despite being years deep into the new Age of AI, there is still surprisingly little clarity around how to systematically approach and model the space in order to find opportunities for investing and building new businesses.
My intention here is to create a simple top-down process for identifying opportunities by analyzing the core components that are critical in any viable AI-driven product or business.
As an entrepreneur, these are the questions I ask myself when deciding which areas look most fertile to pursue. As a VC, you might use this to find green fields for investment or as a tool to evaluate businesses that cross your radar. As a researcher, this may provide new areas to explore and as an industry expert this should help you think about triangulating in on a good opportunity within your domain space.

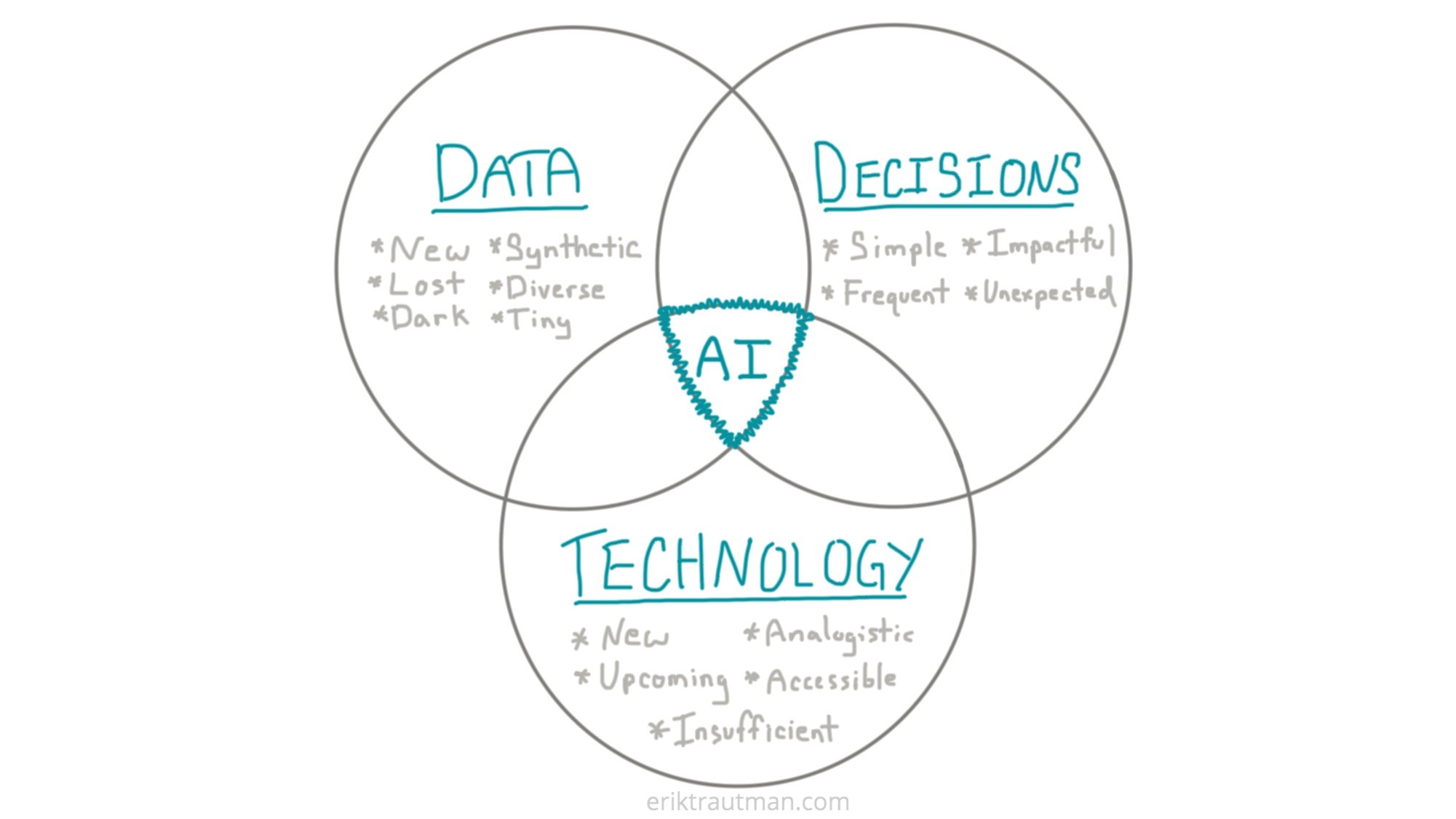
Data, Decisions and Technology
At the core, AI opportunities exist at the intersection of Data, Decisions and Technology.
- Data: Data is the feedstock for AI-driven algorithms so sourcing good data is crucial to a viable opportunity.
- Decisions: The core value of AI is that it enables better decisions so you need to identify valuable decisions to apply it to.
- Technology: Recent progress in AI technologies has been outstanding but also uneven. You need to find a space where the technology creates (or will create) new capabilities.
The way to apply this to opportunity assessment is by thinking through each of these dimensions and looking for the intersections between the three. Sometimes, a breakthrough idea in one area fits naturally with things you already understand about the others.
It should be noted that there are plenty of good ideas which fit only two or even just one of these dimensions but the intention here is to focus on those opportunities which are best suited for AI-driven solutions that can take advantage of the AI Virtuous Cycle.
In any case, I've done a lot of the hard work and created a set of filters and heuristics for getting this process started in each of the categories.
Data: The Feedstock
Most of the search for AI opportunities starts and ends with data. But data comes in a wide range of flavors and how you source it will vary for each. I encourage you to brainstorm how you might source data from any of these methods:
- NEW Pools: Where is data being created by others where there wasn't any before? For example, regulatory or industry changes often require digitization of records. Another approach is to follow the sensors — a whole range of new smart devices (eg watches) are producing gobs of new data. By extension, how can YOU create data where there was none before? What sensors could you use or combine in creative ways to produce new data streams?
- LOST Pools: What data is currently being created that no one is paying attention to? The classic example of this is "process exhaust," where a company produces significant amounts of data in the normal course of doing business without that data actually being core to their business itself.
- DARK Pools: What pools of data couldn't previously be accessed but now can? For example, text records used to be thought of as inaccessible but new NLP technologies have brought them into the light. Another angle is asking who didn't have the incentives to share their data before but might be incentivized now to do so?
- SYNTHETIC Pools: How can you synthetically create a new dataset from existing ones? For example, how Google Maps combined satellite data and street view data to create "areas of interest". This raises interesting questions about strategic data acquisition.
- DIVERSE Pools: How can we expand the amount of data we're inputting to existing models that we assumed already had enough? For example, a new wave of disruptive credit scoring models use a much more diverse pool of data (eg mobile payment histories) than ever before. Sales lead scoring tools are consuming a far broader set of information (eg LinkedIn profiles) than ever before.
- TINY Pools: Where are we collecting data now in ways that are slow and small but could be collected in a much faster or broader way? For example, forestry experts still manually measure the size of trees to understand the carbon capture of a forest where drones should be able to make significant inroads. Anything currently written on paper can be either digitized or fully automated altogether (eg using drones to record daily construction status).
Finally, there are always wildcards worth considering which shake up the whole data chain. GDPR is a good example — how many pools of data have new ripples across their surfaces due to changes made to serve it?
Decisions: The Value
You can only build a business if it solves a meaningful problem. AI is great at making better/faster/cheaper decisions, so a key ideation process is to really dig deep and consider the kinds of decisions that are being made in a given domain space. This is a slightly unusual exercise which takes some imagination — we aren't used to thinking about certain things as decisions.
For example, Spotify's "Discover Weekly" playlist is automatically generated using a combination of multiple models and it addresses the decision of "what song should I play next?" In many cases, you wouldn't have thought of that as a "decision" per se.
The key is to think about user behavior in any situation as a series of task chains glued together by decisions. In many cases, it looks like a tree structure. The point isn't to spend weeks diagramming all the possible decisions in a particular human's life (though that may yield meaningful results) but to focus on a few key sets of decisions as a starting point and think through which of those are most valuable for AI to solve. As we know, AI is great at closing task loops by providing better decisions.
Here are the key types of decisions:
- SIMPLE Decisions: The simplest decisions are easiest to automate. The conventional rule of thumb is "anything a human can do in 1 second or less". For example, removing defective items from an assembly line.
- FREQUENT Decisions: One key decision axis is frequency. Any decision that must be made with high frequency, even if it is low impact, is a good candidate for disrupting with AI. For example, the aforementioned song selection decision.
- IMPACTFUL Decisions: On the other end of the spectrum are the high impact decisions. AI doesn't have to completely take over the decision, only assist to a meaningful degree. For example, the large set of radiologist, doctor and surgeon assistance solutions. What other high stakes decisions could be improved?
- UNEXPECTED Decisions: There are a number of decisions which can be completely disintermediated through the use of AI, effectively rewriting the decisions tree itself. This is a real benefit of many modern approaches, which rely heavily on source data and the ultimate deliverable to skip all the middle steps. For another example in the medical space, imagine a system that can take your vitals and set of test results, make a diagnosis, give a prognosis and prescribe the solution in one step. Note that many of the challenges of explainable AI live in this domain.
Deconstructing decision trees from ordinary behaviors isn't entirely natural but provides a useful approach for honing in on the truly valuable ones and those most vulnerable to AI disruption.
Technology: The Enabler
If Data is the feedstock and Decisions are the target, the Technology is what bridges the gap between the two. But technology isn't meaningful in this context unless it maps to a clear new Capability. Essentially, what can you actually do with it? A particular new Capability is often a marriage of several technologies acting in concert so it's the best place to start.
You can use these categories to think about what capabilities exist or might exist, then map it back to the arc of technology itself:
- NEW Capabilities: What can we do now that we couldn't do before? Even existing technologies don't efficiently propagate across the market. For example, optical character recognition (OCR), natural language processing (NLP), image recognition, etc.
- UPCOMING Capabilities: What new capabilities are opened up by upcoming technology? This isn't just about specific algorithms, it includes capabilities opened up by improvements in processing power, data ingestion, tooling etc. It requires thinking about not just the arc of advancement in a particular technology but the combination of multiple arcs.
- INSUFFICIENT Capabilities: What capabilities have we written off as being insufficient based on current technology? This is less a separation from the prior two than a prompt to think critically about the failures of the past (eg voice assistance) and ask how future technologies might fix the gaps.
- ANALOGISTIC Capabilities: What looks a lot like existing things that we know computers are already really good at? For example, if we view the world through the lens of reinforcement learning (games), data center optimizations or perception and control, what other problem spaces start to look just like these already-solved problems?
- ACCESSIBLE Capabilities: What capabilities are now too expensive or require too much expertise to properly utilize but for which time will add services and reduce cost? This is less about the actual creation of revolutionary new technologies and more about asking what happens when you begin to democratize access to them. For example, when machine learning can be done on edge (eg mobile or embedded) devices instead of only on expensive cloud servers.
Ideating along the arc of technology requires a healthy amount of diligence because it's easy to stop trying after thinking through your favorite tech. That could even be sufficient to highlight new opportunities but note that innovation often hides in the corners as well. A rigorous approach considers as much of the full spectrum of technology as possible.
How to Proceed
The Data, Decisions and Technologies framework is intended to be a model to help you continuously improve your ideation processes as you search for opportunities in the AI space and evaluate existing ones for viability and defensibility. It is helpful to take both a top down approach (whiteboarding ideas in each category in turn) and a bottom up approach (starting with existing ideas and filtering them back through the stack) to get the most value out of it.
In any case, ideation is best done collaboratively. This framework has been generated through dozens of conversations with entrepreneurs, VCs, engineers and strategists and hopefully serves as the seed for many more rigorous and exciting conversations about the kinds of new opportunities we can pursue together.
Do you have your own models for identifying opportunities in AI or want to explore this further? Hit me up on Twitter.
Additional Resources
- HBR's How to Spot a Machine Learning Opportunity, Even If You Aren't a Data Scientist by Kathryn Hume
- Accenture's AI Business Value paper (2016)
- Untapped Opportunities in AI (2014) by Beau Cronin of O'Reilly Media in Forbes